Ухилення xmlrpc php. Змагання з програмування
Організація обробки потоку з ефективним використанням пам'яті
Еліотт Геролд (Elliot Rusty Harold)
Опубліковано 11.10.2007
PHP 5 представив XMLReader , новий клас для читання мови розмітки, що розширюється (XML). На відміну від простого XML або об'єктної моделі документів (DOM), XMLReader працює в потоковому режимі. Тобто, він зчитує документ від початку до кінця. Перш ніж ви побачите його закінчення, можна почати працювати з вмістом документа на його початку. Це робить роботу дуже швидкою, ефективною та дуже економною з точки зору витрат пам'яті. Чим більший розмір документів, які необхідно обробляти, тим важливіше.
libxml
Описуваний XMLReader API ґрунтується на libxml-бібліотеці Gnome Project для C та C++. Насправді XMLReader - це лише тонкий PHP-шар на поверхні API libxml XmlTextReader . XmlTextReader також змодельований на основі (хоча і не має загального коду) .NET класів XmlTextReader та XmlReader .
На відміну від простого API для XML (SAX), XMLReader - більшою мірою приймає парсер (pull parser), ніж передає парсер (push parser). Це означає, що програма перебуває під контролем. Замість того, щоб парсер повідомляв вам, що він бачить, коли він це бачить; ви вказуєте парсеру, коли потрібно переходити до наступного фрагмента документа. Ви запитуєте контент замість реагувати на нього. Інакше кажучи, це можна так XMLReader - це реалізація конструктивного шаблону Iterator (ітератор), а чи не конструктивного шаблону Observer (спостерігач).
Зразок завдання
Почнемо з простого прикладу. Уявіть, що ви пишете PHP-скрипт, який отримує запити XML-RPC і генерує відповіді. Точніше, уявіть, що запити виглядають, як показано у лістингу 1. Кореневий елемент документа methodCall , у якому містяться елементи methodName і params . Назва методу - sqrt. Елемент params містить один елемент param , що включає double - число, квадратний корінь якого потрібно витягти. Області імен не використовуються.
Лістинг 1. Запит XML-RPC
Ось що повинен робити PHP-скрипт:
- Перевірити назву методу та згенерувати сигнал про збій (fault response), якщо це не sqrt (єдиний метод, який може бути оброблений цим сценарієм).
- Знайти аргумент і, якщо він відсутня чи має неправильний тип, згенерувати сигнал про збій.
- В іншому випадку обчислити квадратний корінь.
- Повернути результат у формі, показаній у лістингу 2.
Лістинг 2. Відповідь XML-RPC
Давайте розглянемо крок за кроком.
Ініціалізація парсера та завантаження документа
Першим кроком є створення нового об'єкта парсера. Зробити це просто:
$reader = новий XMLReader();Додавання інформації до вихідних даних, що надсилаються
Якщо ви виявите, що $HTTP_RAW_POST_DATA порожній, додайте наступний рядок у файл php.ini:
always_populate_raw_post_data = On
$request = $HTTP_RAW_POST_DATA; $reader->XML($request);Можна проаналізувати будь-який рядок, звідки ви його не взяли б. Наприклад, це може бути строкова літеральна константа у програмі або вміст файлу. Також можна завантажити дані із зовнішнього URL за допомогою функції open(). Наприклад, наступна інструкція готує один з Atom-каналів для аналізу:
$reader->XML("http://www.cafeaulait.org/today.atom");Звідки ви взяли вихідні дані, програма читання тепер встановлена і готова виконувати аналіз.
Читання документа
Функція read() переміщає парсер наступного маркеру. Найпростіший підхід полягає у виконанні ітерацій циклу while по всьому документу:
while ($reader->read()) ( // обробний код ... )Після закінчення закрийте парсер, щоб звільнити ресурси, які він займає, та переналаштуйте його для наступного документа:
$reader->close();Усередині циклу парсер міститься у певному вузлі: на початку елемента, наприкінці елемента, у текстовому вузлі, у коментарі тощо. Наступні властивості дозволяють дізнатися, що парсер переглядає в даний момент:
- localName - це локальне, попередньо не вказане ім'я вузла.
- name - можливе заздалегідь задане ім'я вузла. Для таких вузлів, які не мають імен, наприклад, коментарів, це #comment, #text, #document, і т. д., як у DOM (об'єктна модель документів).
- namespaceURI – це уніфікований ідентифікатор ресурсу (URI) для простору імен вузла.
- nodeType - це ціле число, що представляє тип вузла - наприклад, 2 для атрибута вузла і 7 - для оператора обробки.
- prefix – це префікс простору імен вузла.
- value – це текстовий зміст вузла.
- hasValue - вірно, якщо вузол має текстове значення і неправильно інакше.
Звичайно, не всі типи вузлів мають всі ці властивості. Наприклад, текстові вузли, розділи CDATA, коментарі, оператори обробки, атрибути, символ пробілу, типи документів та описи XML мають значення. Інші типи вузлів (особливо – елементи та документи) – не мають. Зазвичай програма використовує властивість nodeType визначення того, що проглядається, і видачі відповідної відповіді. У лістингу 3 показаний простий цикл while який використовує ці функції для виведення того, що він переглядає. У лістингу 4 показаний результат цієї програми, коли їй на вхід подається лістинг 1.
Лістинг 3. Що бачить парсер
while ($reader->read()) ( echo $reader->name; if ($reader->hasValue) ( echo ": " . $reader->value; ) echo "\n"; )Лістинг 4. Виведення з лістингу 3
methodCall #text: methodName #text: sqrt methodName #text: params #text: param #text: value double #text: 10 double value #text: param #text: params #text: methodCallБільшість програм негаразд універсальна. Вони приймають вхідні дані в особливій формі та обробляють їх певним чином. У прикладі XML-RPC слід вважати лише один параметр із вхідних даних: елемент double , який має бути лише один. Щоб це зробити, знайдіть початок елемента з ім'ям double:
if ($reader->name == "double" && $reader->nodeelementType == XMLReader::element) ( // ... )Цей елемент також має єдиний текстовий дочірній вузол, який можна зчитувати, переміщуючи парсер до наступного вузла:
if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) ( $reader->read(); respond($reader->value); )Тут функція respond() створює відповідь XML-RPC і надсилає клієнтові. Однак, перш ніж я покажу це, потрібно розповісти ще дещо. Немає гарантії того, що елемент double у документі запиту містить лише один текстовий вузол. Він може містити декілька вузлів, а також коментарі та оператори. Наприклад, це може виглядати так:
Вкладені елементи
У цій схемі є можливий дефект. Вкладені елементи double , наприклад,
Стійке вирішення проблеми має забезпечувати отримання всіх нащадків текстового вузла double, об'єднувати їх у ланцюжок і лише потім конвертувати результат у double. Необхідно уникати будь-яких коментарів чи інших можливих нетекстових вузлів. Це трохи складніше, але, як показано у лістингу 5, не надто.
Лістинг 5. Підсумуйте весь текстовий контент елемента
while ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || ") ( break; ) )Поки що весь інший контент документа можна ігнорувати. (Пізніше я продовжу опис обробки помилок).
Створення відповіді
Як випливає з імені, XMLReader призначений лише для читання. Відповідний клас XMLWriter зараз у розробці, але ще готовий. На щастя, писати XML набагато легше, ніж його зчитувати. По-перше, слід встановити тип носія відповіді, використовуючи функцію header() . Для XML-RPC це application/xml . Наприклад:
header("Content-type: application/xml");Лістинг 6. Відображення XML
function respond($input) ( echo "Можна навіть вставити буквені частини відповіді прямо на сторінку PHP, як і було реалізовано в HTML. Ця технологія показана в лістингу 7.
Лістинг 7. Літерний XML
function respond($input) (?>Обробка помилок
До цього моменту малося на увазі, що вхідний документ оформлений коректно. Однак, цього ніхто не може гарантувати. Як будь-який парсер XML, XMLReader повинен припинити обробку, як тільки виявить помилку оформлення. Якщо це відбувається, функція read() повертає false (брехня).
Теоретично парсер може обробляти дані до першої виявленої ним помилки. У моїх експериментах з маленькими документами, однак він стикається з помилкою майже відразу. Пасер, що лежить в основі, попередньо аналізує велику ділянку документа, кешує його, а потім видає його частинами. Таким чином, він зазвичай визначає помилки на попередньому етапі. Для безпеки краще не беріть на себе відповідальність за те, що зможете виконати аналіз контенту до першої помилки оформлення. Більше того, не припускайте, що не побачите жодного контенту до помилки парсера. Якщо потрібно прийняти тільки повні, коректно оформлені документи, то переконайтеся, що скрипт не робить нічого незворотного до кінця документа.
Якщо парсер виявляє помилку в оформленні, функція read() відображає повідомлення про помилку, аналогічне представленому (якщо налаштований докладний звіт про помилку, як і має бути на сервері розробки):
Warning: XMLReader::read() [function.read]:< value>
Ви, можливо, не захочете копіювати звіт на сторінку HTML, яку надає користувачеві. Найкраще фіксувати повідомлення про помилку в змінному середовищі $php_errormsg . Для цього потрібно увімкнути опцію конфігурації track_errors у файлі php.ini:
track_errors = OnЗа замовчуванням опція track_errors вимкнена, що явно вказано у php.ini, тому не забудьте змінити цей рядок. Якщо ви додасте рядок, показаний вище, на початок php.ini, то рядок track_errors = Off , який написаний нижче, замінить його.
Ця програма повинна надсилати відповіді лише на повні, правильно оформлені вхідні дані. (Також достовірні, але про це пізніше.) Таким чином, потрібно почекати завершення аналізу документа (вихід із циклу while). Тепер перевірте, чи змінилося $php_errormsg . Якщо ні, то документ оформлений коректно, і буде надіслано повідомлення-відповідь XML-RPC. Якщо змінна задана, це означає, що документ оформлений некоректно, і буде надіслано сигнал про збій XML-RPC. Також сигнал про збій відправляється, якщо запитується квадратний корінь негативного числа. Дивіться листинг 8.
Лістинг 8. Перевірка коректного оформлення
// Надсилання запиту (request) $request = $HTTP_RAW_POST_DATA; error_reporting(E_ERROR | E_WARNING | E_PARSE); if (isset($php_errormsg)) unset(($php_errormsg); // створення програми зчитування (reader) $reader = new XMLReader(); // $reader->setRelaxNGсхемою("request.rng"); $reader-> XML($request); $input = ""; while ($reader->read()) ($reader->read()) ( if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE | $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) ( $input .= $reader->value; ) else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double" ) ( break; ) break; ) ) // перевірка коректного оформлення вхідної інформації if (isset($php_errormsg)) fault(21, $php_errormsg);< 0) fault(20, "Cannot take square root of negative number"); else respond($input);Тут наведено спрощену версію загального шаблону обробки потоків XML. Парсер заповнює структуру даних, відповідно до якої виконуються дії, коли документ закінчується. Зазвичай структура даних простіша, ніж сам документ. Тут структура даних особливо проста: єдиний рядок.
Валідація
Версія libxml
У ранніх версіях libxml, бібліотеки, від якої залежить XMLReader, були серйозні недоліки RELAX NG. Переконайтеся, що ви використовуєте хоча б версію 2.06.26. Багато систем, зокрема Mac OS X Tiger, містять ранній випуск із недоліками.
Досі я не надавав великого значення перевірці того, чи дійсно дані знаходяться там, де я думаю. Найпростіший спосіб здійснити цю перевірку – порівняти документ зі схемою. XMLReader підтримує мову опису схеми RELAX NG; у лістингу 9 показана проста схема RELAX NG для цієї конкретної форми запиту XML-RPC.
Лістинг 9. Запит XML-RPC
Схему можна додати безпосередньо до PHP-скрипту у вигляді рядкового літералу за допомогою setRelaxNGSchemaSource() або вважати її із зовнішнього файлу або URL за допомогою setRelaxNGSchema() . Наприклад, за умови, що вміст листингу 9 записано у файлі sqrt.rng, схема завантажуватиметься таким чином:
reader->setRelaxNGSchema("sqrt.rng")Виконайте це ранішечим почнете аналізувати документ. Парсер порівнює документ із схемою під час читання. Щоб перевірити, чи документ є достовірним, викличте функцію isValid() , яка повертає значення true, якщо документ валідний (на даному етапі) і false в іншому випадку. У лістингу 10 показано повну логічно завершену програму, що містить обробку всіх помилок. Програма повинна приймати будь-які достовірні вхідні дані та повертати правильні значення та відхиляти всі неправильні запити. Я також додав метод fault() , який надсилає сигнал про збій XML-RPC, якщо щось іде не так.
Лістинг 10. Повна серверна частина вилучення квадратного кореня XML-RPC
Атрибути
Атрибути не видно при нормальному виконанні аналізу. Щоб рахувати атрибути, необхідно зупинитися на початку елемента і запросити конкретний атрибут або на ім'я або на номер.
Передайте ім'я атрибута, значення якого потрібно знайти у поточному елементі, функції getAttribute() . Наприклад, наступна конструкція вимагає атрибут id поточного елемента:
$id = $reader->getAttribute("id");Якщо атрибут - у просторі імен, наприклад, xlink:href , то викличте getAttributeNS () і передайте локальне ім'я та URI простору імен як перший і другий аргументи відповідно (префікс не має значення). Наприклад, ця інструкція запитує значення атрибуту xlink:href у просторі імен http://www.w3.org/1999/xlink/:
$href = $reader->getAttributeNS ("href", "http://www.w3.org/1999/xlink/");Якщо атрибут не існує, то обидва методи повернуть порожній рядок. (Це неправильно, тому що вони повинні повернути null. Дана реалізація ускладнює можливість розрізняти атрибути, значення яких - порожній рядок, і ті, що взагалі відсутні.)
Порядок атрибутів
У документах XML порядок атрибутів не має значення і не зберігається парсером. Він використовує номери для індексування атрибутів просто задля зручності. Немає гарантії, що перший атрибут у тезі, що відкриває, буде атрибутом 1, другий буде атрибутом 2 і т.д. Не створюйте код, який залежить від порядку атрибутів.
Якщо потрібно знати всі атрибути елемента, а їх імена заздалегідь невідомі, викличте moveToNextAttribute() , коли зчитуюча частина встановлена на елементі. Якщо парсер знаходиться на вузлі атрибута, то можна вважати його ім'я, простір імен та значення за допомогою тих самих властивостей, які використовувалися для елементів. Наприклад, наступний фрагмент коду друкує всі атрибути поточного елемента:
if ($reader->hasAttributes and $reader->nodeType == XMLReader::ELEMENT) ( while ($reader->moveToNextAttribute()) ( echo $reader->name . "="" . $reader->value . "\n"; ) echo "\n"; )Дуже незвичайно для XML API те, що XMLReader дозволяє зчитувати атрибути або спочатку, або з кінцяелемент. Щоб уникнути подвійного відліку, важливо переконатися, що типом вузла є XMLReader::ELEMENT , а не XMLReader::END_ELEMENT , який також може мати атрибути.
Висновок
XMLReader - корисний додаток до інструментарію програміста PHP. На відміну від SimpleXML, це повний парсер XML, який обробляє всі документи, а не тільки деякі з них. На відміну від DOM він може обробляти документи більші, ніж доступна пам'ять. На відміну від SAX, він встановлює контроль над програмою. Якщо PHP-програмам потрібно приймати вхідні дані XML, варто серйозно задуматися про використання XMLReader .
Введення в XML-RPC
У Мережі є багато різних ресурсів, які надають користувачам певну інформацію. Маються на увазі не типові статичні сторінки, а, наприклад, дані, що витягуються з бази даних чи архівів. Це може бути архів фінансових даних (курси валют, дані котирувань цінних паперів), дані про погоду, або більш об'ємна інформація - новини, статті, повідомлення з форумів. Така інформація може представлятися відвідувачеві сторінки, наприклад, через форму, як відповідь на запит, або щоразу генеруватися динамічно. Але труднощі в тому, що часто така інформація потрібна не так кінцевому користувачеві - людині, як іншим системам, програмам, які ці дані будуть використовувати для своїх розрахунків або інших потреб.
Реальний приклад: сторінка банківського сайту, де показуються котирування валют. Якщо ви заходите на сторінку як звичайний користувач через браузер, ви бачите все оформлення сторінки, банери, меню та іншу інформацію, яка "обрамляє" справжню мету пошуку - котирування валют. Якщо вам потрібно вносити ці котирування до свого інтернет-магазину, то нічого іншого не залишиться, як тільки вручну виділити потрібні дані та через буфер обміну перенести на свій сайт. І так доведеться робити щодня. Невже нема виходу?
Якщо вирішувати проблему "в лоб", то відразу напрошується рішення: програма (скрипт на сайті), якій треба дані, отримує сторінку від сервера як "звичайний користувач", розбирає (парсит) отриманий HTML-код і виділяє з нього потрібну інформацію. Це можна зробити або звичайним регулярним виразом, або за допомогою будь-якого html-парсера. Складність підходу – у його неефективності. По-перше, для отримання невеликої порції даних (дані про валюти - це буквально десяток-другий символів) треба отримувати всю сторінку, а це не менше кількох десятків кілобайт. По-друге, при будь-якій зміні коду сторінки, наприклад, дизайн змінився або ще щось, наш алгоритм аналізу доведеться переробляти. Та й ресурсів це відбиратиме порядно.
Тому розробники дійшли рішення - треба розробити якийсь універсальний механізм, який би дозволив прозоро (на рівні протоколу та середовища передачі) і легко обмінюватися даними між програмами, які можуть знаходитися будь-де, бути написаними будь-якою мовою і працювати під управлінням будь-якої операційної системи та на будь-якій апаратній платформі. Такий механізм називають зараз гучними термінами "Веб-сервіси" (web-service), "SOAP", "архітектура, орієнтована на сервіси" (service-oriented architecture). Для обміну даними використовуються відкриті і перевірені часом стандарти - передачі повідомлень протокол HTTP (хоча можна використовувати інші протоколи - SMTP наприклад). Самі дані (у нашому прикладі – курси валют) передаються упакованими у крос-платформний формат – у вигляді XML-документів. Для цього придумано спеціальний стандарт - SOAP.
Так, зараз веб-сервіси, SOAP і XML у всіх на слуху, їх починають активно впроваджувати і великі корпорації типу IBM і Microsoft випускають нові продукти, покликані допомогти тотальному впровадженню веб-сервісів.
Але! Для нашого прикладу з курсами валют, які повинні передаватися з сайту банку в двигун інтернет-магазину, таке рішення буде дуже складним. Адже тільки опис стандарту SOAP займає непристойні півтори тисячі сторінок, і це ще не все. Для практичного використання доведеться вивчити ще роботу зі сторонніми бібліотеками та розширеннями (тільки починаючи з PHP 5.0 до нього входить бібліотека для роботи з SOAP), написати сотні та тисячі рядків свого коду. І все це для отримання кількох літер і цифр - явно дуже важко й нераціонально.
Тому існує ще один, з натяжкою можна сказати альтернативний стандарт на обмін інформацією – XML-RPC. Він був розроблений за участю Microsoft компанією UserLand Software Inc і призначений для уніфікованої передачі даних між програмами через Інтернет. Він може замінити SOAP при побудові простих сервісів, де не потрібні всі "корпоративні" можливості справжніх веб-сервісів.
Що означає абревіатура XML-RPC? RPC розшифровується як Remote Procedure Call – віддалений виклик процедур. Це означає, що програма (неважливо, скрипт на сервері або звичайна програма на клієнтському комп'ютері) може прозоро використовувати метод, який фізично реалізований та виконується на іншому комп'ютері. XML тут застосовується для забезпечення універсального формату опису даних, що передаються. Як транспорт для передачі повідомлень застосовується протокол HTTP, що дозволяє безперешкодно обмінюватися даними через будь-які мережеві пристрої - маршрутизатори, фаєрволи, проксі-сервера.
І так, для використання треба мати: сервер XML-RPC, який надає один або кілька методів, клієнт XML-RPC, який може формувати коректний запит та обробляти відповідь сервера, а також знати необхідні для успішної роботи параметри сервера - адресу, назву методу та параметри, що передаються.
Вся робота з XML-RPC відбувається в режимі "запит-відповідь", в цьому є одна з відмінностей технології від стандарту SOAP, де є і поняття транзакцій, і можливість робити відкладені виклики (коли сервер зберігає запит і відповідає на нього в певний час у майбутньому). Ці додаткові можливості більше стануть у нагоді для потужних корпоративних сервісів, вони значно ускладнюють розробку та підтримку серверів, і ставлять додаткові вимоги до розробників клієнтських рішень.
Процедура роботи з XML-RPC починається із формування запиту. Типовий запит має такий вигляд:
POST/RPC2 HTTP/1.0
User-Agent: eshop-test/1.1.1 (FreeBSD)
Host: server.localnet.com
Content-Type: text/xml
Content-length: 172
У перших рядках формується стандартний заголовок HTTP запиту POST. До обов'язкових параметрів належать host, тип даних (MIME-тип), який має бути text/xml, а також довжина повідомлення. Також у стандарті вказується, що поле User-Agent має бути заповнене, але може мати довільне значення.
Далі йде типовий заголовок XML-документа. Кореневий елемент запиту -
Рядок
Далі задаються параметри, що передаються. Для цього є секція
Після опису всіх параметрів слідують теги, що закривають. Запит та відповідь у XML-RPC – це звичайні документи XML, тому всі теги обов'язково повинні бути закриті. А ось одиночних тегів у XML-RPC немає, хоча у стандарті XML вони є.
Тепер розберемо відповідь сервера. Заголовок HTTP відповіді звичайний, якщо запит успішно оброблений, сервер повертає відповідь HTTP/1.1 200 OK. Також, як у запиті, слід коректно вказати MIME-тип, довжину повідомлення та дату формування відповіді.
Саме тіло відповіді таке:
Тепер замість кореневого тегу
Якщо під час обробки вашого запиту сталася помилка, то замість У відповіді буде елемент
А тепер розглянемо коротко типи даних у XML-RPC. Усього типів даних є 9 - сім простих типів та 2 складних. Кожен тип описується своїм тегом чи набором тегів (для складних типів).
Прості типи:
Цілі числа- тег
Логічний тип- тег
ASCII-рядок- описується тегом
Числа з плаваючою точкою- тег
Дата та час- описується тегом
Останнім простим типом є рядок, закодований у base64, яка описується тегом
Складні типи представлені структурами та масивами. Структура визначається кореневим елементом
Масиви не мають назв і описуються тегом
Звичайно, хтось скаже, що такий перелік типів даних дуже бідний і не дозволяє розвернутися. Так, якщо треба передавати складні об'єкти або великі обсяги даних, то краще використовувати SOAP. А для невеликих, невибагливих додатків цілком підходить і XML-RPC, більш того, дуже часто навіть його можливостей виявляється дуже багато! Якщо врахувати легкість розгортання, дуже велика кількість бібліотек майже для будь-яких мов і платформ, широку підтримку в PHP, то XML-RPC часто просто не має конкурентів. Хоча відразу радити його як універсальне рішення не можна - у кожному конкретному випадку треба вирішувати за обставинами.
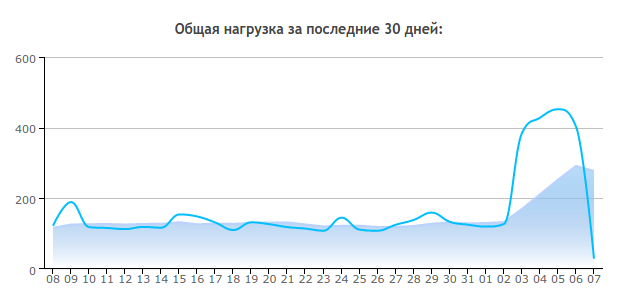
Декілька днів тому я помітив, що навантаження моїх сайтів на хостинг зросло в рази. Якщо зазвичай вона становила в районі 100-120 папуг (CP), то за останні кілька днів вона зросла до 400-500 CP. Нічого хорошого в цьому немає, адже хостер може перевести на дорожчий тариф, а то й зовсім прикрити доступ до сайтів, тож я почав розбиратися.
Але я вибрав метод, який дозволить зберегти функціональність XML-RPC: встановлення плагіна Disable XML-RPC Pingback. Він видаляє лише "небезпечні" методи pingback.ping та pingback.extensions.getPingbacks, залишаючи функціонал XML-RPC. Після встановлення плагін потрібно лише активувати - подальше налаштування не потрібно.
Принагідно я забив всі IP атакуючих у файл.htaccess своїх сайтів, щоб заблокувати їм доступ. Просто дописав у кінець файлу:
Order Allow,Deny Allow from all Deny from 5.196.5.116 37.59.120.214 92.222.35.159
Ось і все тепер ми надійно захистили блог від подальших атак з використанням xmlrpc.php. Наші сайти перестали завантажувати хостинг запитами, а також атакувати за допомогою DDoS сторонні сайти.
Хакери шукають різні шляхи злому ваших сайтів. У більшості випадків, якщо тільки сайт не представляє якоїсь комерційної цінності, це граються діти, намагаючись самоствердитися.
Днями сайти мого хостингу, м'яко кажучи, прилягали. Було видно, що DOS-ят якийсь із сайтів.
А видно це насамперед із статистики використання ресурсів сервера:
Я здивувався з тієї причини, що комерційних ресурсів на хостингу не лежить. Чого, питається, DOS-ть щось? З якою метою?
Що бачимо на діаграмі?
На першому малюнку ми спостерігаємо завантаження процесора. Вона вимірюється у 100% на одне ядро. Десь 15.00 за гринвічем атака почалася, а в районі 21.00 я попросив провайдера щось з цим зробити. Тих підтримка почала перенесення хостингу на інший майстер-сервер. Мабуть, щоб дати можливість використовувати більше системних ресурсів. Годині о 22:00 розпочався переїзд, перевірка цілісності файлів та інші процедури.
Не хотілося навіть возитися — і я просто ліг спати, бо, «ранок вечора мудріший».
Що видно у логах сервера?
Статистика на ранок вже не показувала якихось аномалій. Сайти однаково відкривалися через і далеко ще не відразу, тобто. атака тривала. Чи статистика писалася все ще зі старого сервера, чи це вже були дані майстер-сервера…
Тому я перейшов до вивчення ліг, щоб з'ясувати куди «стукають».

Коли я подивився в логі, стало ясно, що можна не турбуватися — стукає якась школота з однієї й тієї ж ip адреси в /xmlrpc.php одного з моїх сайтів на WordPress. Найімовірніше займається брут-форсом адмінського пароля.
Приємного, звичайно ж, мало, тому що «лежать» і всі інші сайти віртуального сервера. І найприкріше, що я не використовую ці XML сервіси на жодному зі своїх WP сайтів.
Блокуємо XML RPC.
Найпростіше, що ви можете зробити в цій ситуації, - видалити з кореневої папки сайту файл /xmlrpc.php. Сервер не знайшовши скрипу, не запускатиме PHP, витрачатиме ресурси пам'яті та час процесора. Рішення просте, але не гарне. По-перше, хтось може користуватися можливостями RPC. Наприклад, публікувати записи на сайт через один із багатьох Weblog клієнтів. По-друге, файл буде відновлено після чергового оновлення WP.
Якщо ваш сервер працює на Apache, можна блокувати доступ до xmlrpc.php, не видаляючи файл. Потрібно додати наступні інструкції на початок вашого .htaccessфайлу в кореневій директорії сайту WordPress. Це заблокує доступ до файлу з будь-яких адрес.
# XML-RPC DDoS PROTECTION
# XML-RPC DDoS PROTECTION < FilesMatch "^(xmlrpc\.php)" > Order Deny , Allow Deny from all < / FilesMatch > |
У моєму випадку можна було заблокувати лише IP-адресу джерела запитів, т.к. використовувався той самий адресу. Для блокування тільки IP-адреси «школодосера»:
< FilesMatch "^(xmlrpc\.php)" > Order Allow, Deny Deny from 85.93.93.157 Allow from All < / FilesMatch > |
Але якщо ви користуєтеся RPC, то можна скласти білий список адрес, які мають доступ до скрипту xmlrpc.php.
Використання XML-RPC у PHP для публікації матеріалів у LiveJournal.com (ЖЖ)
Для початку вам потрібно завантажити бібліотеку XML-RPC. Найбільш вдалою версією мені здається вільно розповсюджувана через sourceforge " ": Всі приклади нижче будуть наведені для цієї бібліотеки версії 2.2.
Що таке XML-RPC? RPC розшифровується як Remote Procedure Call, відповідно російською це можна перекласти як віддалений виклик процедур за допомогою XML. Сама методика віддаленого виклику процедури відома давно і використовується в таких технологіях як DCOM, SOAP, CORBA. RPC призначений для побудови розподілених клієнт-серверних програм. Це дає можливість будувати програми, які працюють у гетерогенних мережах, наприклад, на комп'ютерах різних систем, проводити віддалену обробку даних та керування віддаленими програмами. Зокрема, цим протоколом користується добре відомий в Росії сайт livejournal.com.
Розглянемо приклад, як можна розмістити кириличний запис (а саме із цим часто виникають проблеми) у ЖЖ. Нижче наведено працюючий код з коментарями:
new xmlrpcval($name, "string"), "password" => new xmlrpcval($password, "string"), "event" => new xmlrpcval($text, "string"), "subject" => new xmlrpcval ($subj, "string"), "lineendings" => new xmlrpcval("unix", "string"), "year" => new xmlrpcval($year, "int"), "mon" => new xmlrpcval( $mon, "int"), "day" => новий xmlrpcval($day, "int"), "hour" => новий xmlrpcval($hour, "int"), "min" => новий xmlrpcval($min , "int"), "ver" => new xmlrpcval(2, "int")); /* на основі масиву створюємо структуру */ $post2 = array(new xmlrpcval($post, "struct")); /* створюємо XML повідомлення для сервера */ $f = new xmlrpcmsg("LJ.XMLRPC.postevent", $post2); /* описуємо сервер */ $c = new xmlrpc_client("/interface/xmlrpc", "www.livejournal.com", 80); $c->request_charset_encoding = "UTF-8"; /* за бажанням дивимося на XML-код того, що відправиться на сервер */ echo nl2br(htmlentities($f->serialize())); /* надсилаємо XML повідомлення на сервер */ $r = $c->send($f); /* аналізуємо результат */ if(!$r->faultCode()) ( /* повідомлення прийнято успішно і повернувся XML-результат */ $v = php_xmlrpc_decode($r->value()); print_r($v); ) else ( /* сервер повернув помилку */ print "An error occurred: "; print "Code: ".htmlspecialchars($r->faultCode()); print "Reason: "".htmlspecialchars($r->faultString( )).""\n"; ) ?>
У цьому прикладі розглянуто лише один метод LJ.XMLRPC.postevent - повний список можливих команд та їх синтаксис (англійською мовою) доступний за адресою: