Який процесор розкриє відеокарту? Крім спостереження за виробництвом, для виявлення вузьких місць використовуються такі інструменти.
FX проти Core i7 Шукаємо вузькі місця із конфігурацією Eyefinity
Ми бачили, як кожні три-чотири роки продуктивність процесорів подвоювалася. І все ж найвибагливіші ігрові двигуни, які ми тестували, також старі, як процесори Core 2 Duo. Звичайно, вузькі місця з боку CPU повинні були піти в минуле, чи не так? Як виявилось, швидкість GPU зростає ще швидше, ніж продуктивність центрального процесора. Таким чином, суперечка про покупку більш швидкого CPU або нарощування графічної потужності продовжується.
Але завжди настає момент, коли сперечатися безглуздо. Для нас він настав, коли ігри почали плавно працювати на найбільшому моніторі з рідною роздільною здатністю 2560x1600. І якщо швидший компонент зможе забезпечити в середньому 200, а не 120 кадрів на секунду, різниця все одно не буде помітна.
У відповідь на відсутність більш високих дозволів для швидких графічних адаптерів AMD представила технологію Eyefinity, а Nvidia – Surround. Обидві технології дозволяють грати більш ніж на одному моніторі, і для GPU high-end класу робота на роздільній здатності 5760×1080 стала об'єктивною реальністю. По суті, три дисплеї з роздільною здатністю 1920×1080 обійдуться дешевше і вражають вас більше, ніж один екран на 2560×1600. Звідси виникла причина додатково витратитися більш потужні графічні рішення.
Але чи дійсно необхідний потужний процесор, щоб грати без "гальм" на роздільній здатності 5760x1080? Питання виявилося цікавим.
Нещодавно AMD представила нову архітектуру, і ми купили боксовий FX-8350. у статті "Огляд та тест AMD FX-8350: чи виправить Piledriver недоліки Bulldozer?"у новому процесорі нам сподобалося багато чого.
З економічної точки зору, у цьому порівнянні Intel доведеться довести, що він не тільки швидше за чіп AMD в іграх, але й виправдовує високу різницю в ціні.


Обидві материнські плати відносяться до сімейства Asus Sabertooth, проте за модель з роз'ємом LGA 1155 компанія вимагає більш високу ціну, що ще ускладнює становище Intel щодо бюджету. Ми спеціально вибрали ці платформи, щоб порівняння продуктивності було максимально справедливим, при цьому вартість не приймалася.
FX проти Core i7 Конфігурація та тести
Поки що ми чекали появи в тестлабі FX-8350, провели тести боксового Враховуючи, що процесор AMD без проблем досягає 4,4 ГГц, ми розпочали тестування чіпа Intel на такій самій частоті. Згодом з'ясувалося, що ми недооцінили наші зразки, оскільки обидва CPU досягли 4,5 ГГц на вибраному рівні напруги.
Нам не хотілося відкладати публікацію через повторне тестування на більш високих частотах, тому було вирішено залишити результати тестів на частоті 4,4 ГГц.
| Тестова конфігурація | |
| CPU Intel | Intel Core i7-3770K (Ivy Bridge): 3,5 ГГц, 8 Мбайт загального кешу L3, LGA 1155 розгін до 4,4 ГГц на 1,25 В |
| Материнська плата Intel | Asus Sabertooth Z77, BIOS 1504 (08/03/2012) |
| Кулер CPU Intel | Thermalright MUX-120 w/Zalman ZM-STG1 Paste |
| CPU AMD | AMD FX-8350 (Vishera): 4,0 ГГц, 8 Мбайт загального кешу L3, Socket AM3+ розгін до 4,4 ГГц на 1,35 В |
| Материнська плата AMD | Asus Sabertooth 990FX, BIOS 1604 (10/24/2012) |
| Кулер CPU AMD | Sunbeamtech Core-Contact Freezer w/Zalman ZM-STG1 Paste |
| Мережа | Вбудований контролер Gigabit LAN |
| Пам'ять | G.Skill F3-17600CL9Q-16GBXLD (16 Гбайт) DDR3-2200 CAS 9-11-9-36 1,65 В |
| Відеокарта | 2 x MSI R7970-2PMD3GD5/OC: GPU, 1010 МГц GDDR5-5500 |
| Накопичувач | Mushkin Chronos Deluxe DX 240 Гбайт, SATA 6 Гбіт/с SSD |
| живлення | Seasonic X760 SS-760KM: ATX12V v2.3, EPS12V, 80 PLUS Gold |
| ПЗ та драйвера | |
| Операційна система | Microsoft Windows 8 Professional RTM x64 |
| Графічний драйвер | AMD Catalyst 12.10 |
Завдяки високій ефективності та швидкій установці, вже кілька років ми використовуємо кулери Thermalright MUX-120 та Sunbeamtech Core Contact Freezer. Однак монтажні скоби, які йдуть у комплекті з цими моделями, не взаємозамінні.


Модулі пам'яті G.Skill F3-17600CL9Q-16GBXLD мають характеристику DDR3-2200 CAS 9 і використовують профілі Intel XMP для напівавтоматичної конфігурації. Sabertooth 990FX використовує значення XMP через Asus DOCP.

Блок живлення Seasonic X760 забезпечує високу ефективність, необхідну оцінки відмінностей платформ.

StarCraft II не підтримує технологію AMD Eyefinity, тому ми вирішили використовувати старіші ігри: Aliens vs. Predator та Metro 2033.
| Конфігурація тестів (3D-ігри) | |
| Aliens vs. Predator | з використанням AvP Tool v.1.03, SSAO/тесселяція/тіні вкл. Тестова конфігурація 1: якість текстур High, без AA, 4x AF Тестова конфігурація 2: якість текстур Very High, 4x AA, 16x AF |
| Battlefield 3 | Режим кампанії, Going Hunting 90-секунд Fraps Тестове налаштування 1: якість Medium (без AA, 4x AF) Тестове налаштування 2: якість Ultra (4x AA, 16x AF) |
| F1 2012 | Версія Steam, вбудований бенчмарк Тестове налаштування 1: якість High, без AA Тестове налаштування 2: якість Ultra, 8x AA |
| Elder Scrolls V: Skyrim | Оновлення 1.7, Celedon Aethirborn рівень 6, 25-секунд Fraps Тестове налаштування 1: DX11, рівень деталізації High без AA, 8x AF, FXAA вкл. Тестове налаштування 2: DX11, рівень деталізації Ultra, 8x AA, 16x AF, FXAA вкл. |
| Metro 2033 | Повна версія, вбудований бенчмарк, сцена "Frontline" Тестове налаштування 1: DX11, High, AAA, 4x AF, без PhysX, без DoF Тестове налаштування 2: DX11, Very High, 4x AA, 16x AF, без PhysX, DoF вкл. |
FX проти Core i7 Результати тестів
Battlefield 3, F1 2012 та Skyrim
Але спочатку давайте поглянемо на енергоспоживання та ефективність.

Енергоспоживання не розігнаного FX-8350У порівнянні з чіпом Intel не так і страшно, хоча практично воно вище. Однак на графіку ми не бачимо картини загалом. Ми не бачили, щоб чіп працював на частоті 4 ГГц при постійному навантаженні на базових налаштуваннях. Замість цього, при обробці восьми потоків Prime95 він зменшив множник і напругу, щоб залишитися в межах заявленого теплового пакета. Тротлінг штучно стримує енергоспоживання CPU. Установка фіксованого множника та напруги помітно підвищує цей показник процесора Vishera при розгоні.
У той же час, не всі ігри можуть задіяти можливість процесора FX-8350обробляти вісім потоків даних одночасно, отже вони ніколи не зможуть довести чіп до спрацьовування механізму троттлінгу.

Як уже зазначалося, під час ігор на нерозігнаному FX-8350тротлінг не активується, оскільки більшість ігор не можуть повністю завантажити процесор. Насправді ігри вигідно використовують технологію Turbo Core, що підвищує частоту процесора до 4,2 ГГц. Найгірше чіп AMD показав себе на діаграмі середньої продуктивності, де Intel помітно виходить уперед.

Для діаграми ефективності ми використовуємо середню споживану потужність і середню продуктивність всіх чотирьох змін як середній показник. У цій діаграмі продуктивність на ват процесора AMD FX-8350становить приблизно дві третини від результату Intel.
FX проти Core i7 Чи зможе AMD FX наздогнати Radeon HD 7970?
Коли ми говоримо про непоганий і доступний залізо, любимо використовувати такі фрази як "80% продуктивності за 60% вартості". Ці показники завжди дуже чесні, оскільки в нас уже стало звичкою вимірювати продуктивність, споживану потужність і ефективність. Однак у них враховується вартість лише одного компонента, а компоненти, як правило, самостійно працювати не можуть.
Додавши компоненти, використані у сьогоднішньому огляді, ціна системи на базі Intel зросла до $1900, а платформи AMD до $1724, це без урахування корпусів, периферії та операційної системи. Якщо розглядати готові рішення, то варто додати ще приблизно $80 за корпус, в результаті отримуємо $1984 у Intel і $1804 у AMD. Економія на готовій конфігурації із процесором AMD становить $180, у відсотковому співвідношенні від загальної вартості системи це небагато. Інакше кажучи, інші компоненти персонального комп'ютера high-end класу применшують значення вигіднішої ціни процесора.

У результаті у нас залишається два абсолютно упереджені способи порівняння ціни та продуктивності. Ми відкрито зізналися, тому сподіваємось, що нас не засуджуватимуть за представлені результати.
Для AMD вигідніше, якщо ми включимо лише вартість системної плати та CPU та збільшимо вигоду. Вийде така діаграма:

Як третя альтернатива можна розглядати материнську плату і процесор як апгрейд, припускаючи, що корпус, блок живлення, пам'ять і накопичувачі залишилися від минулої системи. Найімовірніше, пара відеокарт Radeon HD 7970у старої конфігурації не використовувалася, тому найрозумніше брати до уваги процесори, системні плати, і графічні адаптери. Таким чином, до списку ми додаємо дві відеокарти із GPU Tahiti за $800.

AMD FX-8350виглядає вигідніше ніж Intel (особливо в іграх, на вибраних нами налаштуваннях) лише в одному випадку: коли решта системи "безкоштовна". Оскільки інші компоненти не можуть бути безкоштовними, FX-8350теж зможе стати вигідним придбанням для ігор.
Intel та відеокарти AMD
Результати наших тестів вже давно показали, що графічні чіпи ATI більш процесорозалежні, ніж чіпи Nvidia. В результаті, при тестуванні GPU high-end класу, ми оснащуємо наші тестові стенди процесорами Intel, оминаючи недоліки платформи, які можуть завадити ізоляції графічної продуктивності та несприятливо позначитися на результатах.
Ми сподівалися, що вихід AMD Piledriverзмінить ситуацію, але навіть кількох вражаючих удосконалень виявилося замало, щоб команда розробників CPU порівнялася з ефективністю команди розробників графічних рішень у самій AMD. Що ж, почекаємо виходу чіпів AMD на базі архітектури Steamroller, яка обіцяє бути на 15% продуктивнішою за Piledriver.
Технічний прогрес не у всіх областях рухається поступово, це очевидно. У цій статті ми розглянемо, які ж вузли коли поліпшували свої параметри повільніше інших, стаючи слабким ланкою. Отже, сьогоднішня тема – еволюція слабких ланок – як вони виникали, впливали і як усувалися.
Процесор
З ранніх персональних комп'ютерів переважна більшість обчислень лягала на CPU. Пов'язано це було з тим, що чіпи були не дуже дешеві, тому більшість периферії використовувала під свої потреби процесорний час. Та й периферії самої тоді було дуже мало. Незабаром із розширенням сфери застосування ПК, ця парадигма була переглянута. Настав час розквіту різноманітних карт розширення.
За часів «двушок» і «троячок» (це не Pentium'и II та III, як може вирішити молодь, а процесори i286 та i386) завдання ставилися перед системами не дуже складні, в основному офісні програми та розрахунки. Карти розширення вже частиною розвантажували процесор, наприклад, MPEG-декодер, який займався дешифруванням файлів, стислих MPEG, робив це без участі CPU. Трохи згодом почали розроблятися стандарти, які менше навантажували процесор під час обміну даними. Прикладом була шина PCI (що з'явилася, починаючи з i486), робота з якої меншою мірою навантажувала процесор. Також до таких прикладів можна віднести PIO та (U)DMA.
Процесори нарощували потужність непоганими темпами, з'явився множник, оскільки швидкість системної шини була обмежена, і кеш – для маскування запитів у оперативну пам'ять, що працює на меншій частоті. Процесор все ще залишався слабкою ланкою, і від нього майже повністю залежала швидкість роботи.
Тим часом, компанія Intel після випуску непоганого процесора Pentium випускає нове покоління – Pentium MMX. Вона хотіла змінити стан справ та перенести розрахунки на процесор. У цьому непогано допоміг набір інструкцій MMX – MultiMedia eXtensions, що призначався для прискорення робіт із обробкою звуку та відео. З його допомогою почала нормально програватися музика формату mp3, і можна було досягти прийнятного відтворення MPEG4 засобами CPU.
Перші пробки у шині
Системи з урахуванням процесора Pentium MMX вже більше упиралися в ПСП (пропускну здатність пам'яті). Шина в 66 МГц для нового процесора була пляшковим шийком, незважаючи на перехід на новий тип пам'яті SDRAM, який покращив продуктивність у перерахунку на мегагерц. Тому дуже популярним став розгін по шині, коли виставляли шину 83 МГц (або 75 МГц) і отримували дуже помітний приріст. Найчастіше навіть менша підсумкова частота процесора компенсувалася більшою частотою шини. Вперше більшу швидкість вдавалося досягти при меншій частоті. Ще одним пляшковим шийкою став обсяг оперативної пам'яті. Для SIMM-пам'яті це був максимум 64 Мб, але частіше стояло 32 Мб або зовсім 16. Це сильно ускладнювало використання програм, оскільки кожна нова версія Windows, як відомо, любить «їсти багато смачної рами» (c). Неподано ходять чутки щодо змови виробників пам'яті з корпорацією Microsoft.
Intel тим часом почала розвивати дорогу і тому не дуже популярну платформу Socket8, а AMD продовжила розвивати Socket7. На жаль, остання використала у своїх продуктах повільний FPU (Floating Point Unit– модуль операцій з дробовими числами), створений щойно купленої тоді компанією Nexgen, що тягло у себе відставання від конкурента у мультимедійних завданнях – насамперед, іграх. Переведення на шину 100 МГц дав процесорам необхідну ПСП, а повношвидкісний кеш другого рівня в 256 Кб на процесорі AMD K6-3 настільки покращив ситуацію, що швидкість системи характеризувалася тільки частотою процесора, а не шини. Хоча, частково, це було пов'язано з повільним FPU. Офісні програми, що залежать від потужності ALU, завдяки швидкій підсистемі пам'яті працювали швидше за рішення конкурента.
Чіпсети
Intel відмовилася від дорогих Pentium Pro, у яких кристал кешу L2 був інтегрований у процесор і випустила Pentium II. Цей CPU мав ядро, дуже схоже на ядро Pentium MMX. Головними відмінностями стали кеш L2, який розміщувався на картриджі процесора і працював на половині частоти ядра, а нова шина – AGTL. За допомогою нових чіпсетів (зокрема, i440BX) вдалося підвищити частоту шини до 100 МГц та, відповідно, ПСП. По ефективності (стосовно швидкості випадкового читання до теоретичної) ці чіпсети стали одними з найкращих, і до цього дня Intel не змогла побити цей показник. Чіпсети серії i440BX мали одну слабку ланку - південний мост, функціональність якого вже не задовольняла вимог того часу. Використовувався старий південний міст серії i430, що застосовується в системах на базі Pentium I. Саме ця обставина, як і зв'язок між чіпсетами по шині PCI, спонукало виробників до випуску гібридів, що містять північний міст i440BX і південний міст VIA (686A/B).
Тим часом, Intel демонструє програвання DVD-фільму без допоміжних карт. Але Pentium II не отримав великого визнання через високу вартість. Очевидною стала потреба у випуску дешевих аналогів. Перша спроба – Intel Celeron без кешу L2 – стала невдалою: за швидкістю Covington'и дуже програвали конкурентам і ціни своєї не виправдовували. Тоді Intel робить другу спробу, що виявилася вдалою, - ядро Mendocino, що полюбилося оверклокерам, що має вдвічі менший об'єм кешу (128 Кб проти 256 Кб у Pentium II), але працює на вдвічі більшій частоті (на частоті процесора, не вполовину ІІ). За рахунок цього швидкість у більшості завдань була не нижчою, а менша ціна приваблювала покупців.
Перше 3D і знову шина
Відразу після виходу Pentium MMX розпочалася популяризація 3D-технологій. Спочатку це були професійні програми для розробки моделей та графіки, але справжню еру відкрили 3D-ігри, а точніше, 3D-прискорювачі Voodoo, створені компанією 3dfx. Ці прискорювачі стали першими масовими картами для створення 3D сцен, які розвантажували процесор при рендерингу. Саме з того часу й пішов відлік еволюції тривимірних ігор. Досить швидко розрахунок сцени силами центрального процесора став програвати виконаному засобами відеоприскорювача як у швидкості, і якості.
З появою нової потужної підсистеми - графічної, що стала за обсягом даних суперничати з центральним процесором, вилізло нове пляшкове шийка - шина PCI. Зокрема, карти Voodoo 3 і старші отримували збільшення швидкості вже просто при розгоні шини PCI до 37.5 або 41.5 МГц. Очевидно, що виникла потреба у забезпеченні відеокарт досить швидкою шиною. Такою шиною (а точніше портом) стала AGP – Accelerated Graphics Port. Як випливає із назви, це спеціалізована графічна шина, і за специфікацією вона могла мати лише один слот. Перша версія AGP підтримувала швидкості AGP 1x та 2x, що відповідало одноразовій та дворазовій швидкості PCI 32/66, тобто 266 та 533 Мб/с. Повільна версія була додана для сумісності, а саме з нею виникали чималий час проблеми. Причому проблеми були з усіма чіпсетами, крім випущених Intel. За чутками, ці проблеми були пов'язані з наявністю ліцензії тільки у цієї компанії та її перешкоджання розвитку конкуруючої платформи Socket7.
AGP покращив стан справ, і графічний порт перестав бути вузьким місцем. Відеокарти перейшли на нього дуже швидко, але платформа Socket7 майже до кінця страждала від проблем із сумісністю. Лише останні чіпсети та драйвери змогли цю ситуацію покращити, але й тоді виникали нюанси.
І гвинти туди!
Настав час Coppermine, виросли частоти, підросла швидкодія, нові відеокарти покращили продуктивність та примножили конвеєри та пам'ять. Комп'ютер уже став мультимедійним центром – на ньому програвали музику та дивилися фільми. Слабкі за характеристиками інтегровані звукові карти поступаються позицією SBLive!, що стали народним вибором. Але щось перешкоджало повній ідилії. Що це було?
Цим фактором стали жорсткі диски, зростання обсягу яких сповільнилося і зупинилося на позначці близько 40 Гб. Для колекціонерів фільмів (тоді MPEG4) це викликало труднощі. Незабаром проблема була вирішена, і досить швидко - диски дорослі обсягом до 80 Гб і вище і перестали хвилювати більшість користувачів.
AMD випускає дуже хорошу платформу – Socket A та процесор архітектури K7, названий маркетологами Athlon (технічна назва Argon), а також бюджетний Duron. У Атлонів сильними сторонами були шина і потужний FPU, що робило його чудовим процесором для серйозних розрахунків та ігор, залишаючи його конкуренту – Pentium 4 – роль офісних машин, де, втім, потужні системи ніколи не були потрібні. Ранні Duron мали дуже невеликий обсяг кешу та частоту шини, що ускладнювало його конкуренцію з Intel Celeron (Tualatin). Але через кращу масштабованість (через більш швидкісну шину) вони краще відгукувалися на зростання частоти, і тому старші моделі вже спокійно обганяли рішення Intel.
Між двома мостами
У цей період з'явилося одразу два вузькі місця. Перше – це шина між мостами. Зазвичай цих цілей використовувалася PCI. Варто згадати, що PCI у варіанті, що використовується в настільних комп'ютерах, має теоретичну пропускну здатність в 133 Мб/с. Насправді швидкість залежить від чіпсету та застосування та варіюється від 90 до 120 Мб/с. На додаток до цього пропускна спроможність розділяється між усіма пристроями, які до неї підключені. Якщо у нас є два канали IDE з теоретичною пропускною здатністю 100 Мб/с (ATA-100), підключених до шини з теоретичною пропускною здатністю 133 Мб/с, то проблема очевидна. LPC, PS/2, SMBus, AC97 мають низькі вимоги до пропускної спроможності. Зате Ethernet, ATA 100/133, PCI, USB 1.1/2.0 вже оперують швидкостями, які можна порівняти з міжмостовим інтерфейсом. Довгий час проблеми не було. USB не використовувався, Ethernet був нечасто і в основному на швидкості 100 Мбіт/c (12.5 Мб/c), а жорсткі диски не могли навіть близько підійти до максимуму швидкості інтерфейсу. Але час минав, і ситуація змінювалася. Вирішили зробити спеціальну межхабовую (між мостами) шину.
VIA, SiS та Intel випустили свої варіанти шин. Відрізнялися вони насамперед пропускними здібностями. Починалися вони з PCI 32/66 - 233 Мб/с, але було зроблено головне - шина PCI була виділена лише під власні пристрої, і через неї не потрібно було передавати дані іншим шинам. Це покращило швидкість роботи з периферією (щодо архітектури мостів).
Нарощувалась і пропускна спроможність графічного порту. Впроваджувалась можливість роботи з режимами Fast Writes, що дозволяли писати дані у відеопам'ять безпосередньо, минаючи системну пам'ять, і Side Band Addressing, що використовували для передачі додаткову частину шини в 8 біт, зазвичай призначену для передачі технічних даних. Приріст від використання FW досягався тільки при високому навантаженні на процесор, в інших випадках це давало мізерний приріст. Так, відмінність режиму 8x від 4x перебувала у межах похибки.
Процесорозалежність
Ще одним пляшковим шийкою, актуальним і до цього дня, стала процесорозалежність. Це виникло результаті стрімкого розвитку відеокарт і означало недостатню потужність зв'язки «процесор – чіпсет – пам'ять» стосовно відеокарті. Адже кількість кадрів у грі визначається не лише відеокартою, а й цим зв'язуванням, оскільки саме остання надає карті інструкції та дані, які потрібно обробити. Якщо зв'язка не встигає, то відеопідсистема упреться в стелю, що визначається переважно нею. Така стеля залежатиме від потужності карти і настройок, що використовуються, але є і карти, що володіють такою стелею при будь-яких налаштуваннях у певній грі або при однакових налаштуваннях, але в більшості сучасних їй ігор практично при будь-яких процесорах. Наприклад, карта GeForce 3 сильно упиралася у продуктивність процесорів Puntium III та Pentium 4 на ядрі Willamete. Трохи старшої моделі GeForce 4 Ti вже не вистачало Athlon'ів 2100+-2400+, і приріст при покращенні характеристик зв'язки був дуже помітним.
Як покращувалися характеристики? Спочатку AMD, користуючись результатами розробленої ефективної архітектури, просто підвищувала частоту процесорів і покращувала технологічний процес, а виробники чіпсетів – пропускну здатність пам'яті. Intel продовжувала слідувати політиці нарощування тактових частот, благо архітектура Netburst саме до цього й мала. Процесори Intel на ядрах Willamete, Northwood із шиною 400QPB (quad pumped bus) програвали конкуруючим рішенням із шиною 266 МГц. Після впровадження 533QPB процесори зрівнялися у продуктивності. Але потім Intel замість 667-МГц шини, запровадженої в серверних рішеннях, вирішила процесори для настільних комп'ютерів перевести одразу на шину 800 МГц, щоб зробити запас потужності для конкуренції з ядром Barton та новим топом Athlon XP 3200+. Процесори Intel сильно упиралися у частоту шини, і навіть 533QPB не вистачало для забезпечення потоком даних у достатньому обсязі. Саме тому вийшов 3.0-ГГц CPU на шині 800 МГц обганяв у всіх, за винятком, можливо, малого числа, додатках процесор 3.06 МГц на шині 533 МГц.
Також було введено підтримку нових частотних режимів для пам'яті, і з'явився двоканальний режим. Зроблено це було для вирівнювання пропускної спроможності шини процесора та пам'яті. Двоканальний режим DDR саме відповідав QDR на тій же частоті.
Для AMD двоканальний режим був формальністю та давав ледь помітний приріст. Нове ядро Prescott не принесло однозначного приросту в швидкості і подекуди програвало старому Northwood. Основною його метою був переведення на новий техпроцес і можливість подальшого зростання частот. Тепловиділення сильно зросло у зв'язку зі струмами витоку, що поставило хрест на випуску моделі, що працює на частоті 4.0 ГГц.
Через стелю до нової пам'яті
Покоління Radeon 9700/9800 та GeForce 5 для процесорів того часу проблем із процесорозалежністю не викликало. Зате покоління GeForce 6 поставило більшість систем на коліна, оскільки приріст продуктивності був дуже помітним, а тому процесорозалежність вище. Топові процесори на ядрах Barton (Athlon XP 2500+ – 3200+) та Northwood/Prescott (3.0-3.4 МГц 800FSB) уперлися у нову межу – частотну межу пам'яті та шину. Особливо від цього страждала AMD – шина 400 МГц була недостатньою для реалізації потужності FPU. Pentium 4 ситуація була кращою і при мінімальних таймінгах вони демонстрували хороші результати. Але JEDEC не хотіла сертифікувати більш високочастотні модулі пам'яті, що володіють меншими затримками. Тому варіанта було два: або складний чотириканальний режим, або перехід на DDR2. Сталося останнє і була представлена платформа LGA775 (Socket T). Шина залишалася тією ж, але частоти пам'яті були обмежені 400 МГц, лише починалися з неї.
AMD вирішила проблему краще з погляду масштабованості. Покоління K8, що носило технічну назву Hammer, окрім збільшення кількості інструкцій за такт (почасти через коротший конвеєр), мав дві нововведення із заділом на майбутнє. Ними стали вбудований контролер пам'яті (а точніше північний міст з більшою частиною його функціоналу) і швидка універсальна шина HyperTransport, яка служила для зв'язку процесора з чіпсетом або процесорів між собою в багатопроцесорній системі. Вбудований контролер пам'яті дозволив уникнути слабкої ланки – зв'язування «чіпсет – процесор». FSB як така перестала, була лише шина пам'яті і шина HT.
Це дозволило Athlon'ам 64 легко обігнати існуючі рішення Intel на архітектурі Netburst та показати ущербність ідеології довгого конвеєра. Tejas мав багато проблем і не побачив світ. Ці процесори легко реалізовували потенціал карт GeForce 6, як і старші Pentium 4.
Але тут виникло нововведення, що зробило процесори слабкою ланкою надовго. Ім'я йому – multi-GPU. Вирішено було відродити ідеї 3dfx SLI і втілити в NVIDIA SLI. ATI відповіла симетрично та випустила CrossFire. Це були технології обробки сцен силами двох карт. Подвоєна теоретична потужність відеопідсистеми та розрахунки, пов'язані з розбиттям кадру на частини за рахунок процесора, призвели до перекосу системи. Старші Athlon 64 навантажували таку зв'язку лише у великих дозволах. Вихід GeForce 7 та ATI Radeon X1000 ще більше збільшив цей дисбаланс.
Попутно було розроблено нову шину PCI Express. Ця двонаправлена послідовна шина призначена для периферії і має дуже високу швидкість. Вона прийшла на заміну AGP та PCI, хоч і не витіснила її повністю. Зважаючи на універсальність, швидкість і дешевизну реалізації вона швидко витіснила AGP, хоча і не принесла на той час ніякого приросту в швидкості. Різниці між ними не було. Але з погляду уніфікації це був дуже добрий крок. Зараз вже випускаються плати з підтримкою PCI-E 2.0, що має вдвічі більшу пропускну здатність (500 Мб/с у кожну сторону проти колишніх 250 Мб/с на одну лінію). Приросту нинішніх відеокарт це також не дало. Різниця між різними режимами PCI-E можлива лише у разі нестачі відеопам'яті, що означає дисбаланс для самої карти. Такою картою є GeForce 8800GTS 320 Mб – вона дуже чуйно реагує на зміну режиму PCI-E. Але брати незбалансовану карту, тільки щоб оцінити приріст від PCI-E 2.0, – рішення5 не найрозумніше. Інша справа, карти з підтримкою Turbocache та Hypermemory – технологій використання оперативної пам'яті як відеопам'ять. Тут приріст у плані пропускної спроможності пам'яті буде приблизно дворазовим, що позитивно позначиться на продуктивності.
Чи достатньо відеокарті пам'яті можна подивитися у будь-якому огляді пристроїв з різними обсягами VRAM. Там, де спостерігатиметься різке падіння кадрів за секунду, є брак VideoRAM. Але буває, що різниця стає помітна тільки при неграбних режимах - роздільній здатності 2560х1600 і AA/AF на максимум. Тоді різниця 4 і 8 кадрів на секунду хоч і буде дворазовою, але очевидно, що обидва режими неможливі в реальних умовах, тому й до уваги їх брати не варто.
Нова відповідь відеочіпам
Вихід нової архітектури Core 2 (технічна назва Conroe) покращив ситуацію із процесорозалежністю та рішення на GeForce 7 SLI завантажував без особливих проблем. Але подоспелі Quad SLI і GeForce 8 взяли реванш, відновивши перекіс. Так продовжується і досі. Ситуація лише погіршилася з виходом 3-way SLI і підготовкою до виходу Quad SLI на GeForce 8800 і Crossfire X 3-way і 4-way. Вихід Wolfdale трохи підвищив тактові частоти, але й розгону цього процесора мало, щоб нормально завантажити такі відеосистеми. 64-бітові ігри – велика рідкість, а приріст у цьому режимі спостерігається у поодиноких випадках. Ігри, які отримують приріст від чотирьох ядер, можна перерахувати на пальцях однієї руки інваліда. Як завжди, всіх витягує Microsoft, завантажуючи своєю новою ОС і пам'ять, і процесор за здорово живеш. Приховано оголошується, що технології 3-way SLI та Crossfire X будуть працювати виключно під Vista. Враховуючи апетити цієї, можливо, геймери будуть змушені брати чотириядерні процесори. Пов'язано це з більш рівномірним, ніж у Windoes XP, завантаженням ядер. Якщо вона повинна від'їдати неабияку частку процесорного часу, то нехай хоч від'їдає ядра, які грою все одно не використовуються. Проте маю сумнів, що нова операційна система задовольниться даними на відкуп ядрами.
Платформа Intel зживає себе. Чотири ядра вже сильно страждають від нестачі пропускної спроможності пам'яті та затримок, пов'язаних із перемиканнями шини. Шина розділяється, і на перехоплення ядром шини під свій контроль потрібен час. При двох ядрах це терпимо, але на чотирьох вплив тимчасових втрат стає помітнішим. Також системна шина давно не встигає за ПСП. Вплив даного фактора був ослаблений покращенням ефективності асинхронного режиму, що Intel непогано реалізувала. Робочі станції ще більшою мірою страждають від цього з вини невдалого чіпсету, контролер пам'яті якого забезпечує лише до 33% від теоретичного ПСП. Приклад тому – програш платформи Intel Skulltrail у більшості ігрових програм (3Dmark06 CPU test – не ігровий додаток) навіть при використанні однакових відеокарт. Тому Intel оголосила про нове покоління Nehalem, яке займеться використанням інфраструктури, дуже схожої з розробками AMD - вбудований контролер пам'яті і шина для периферії QPI (технічна назва CSI). Це покращить масштабованість платформи та дасть позитивні результати у двопроцесорних та багатоядерних конфігураціях.
AMD зараз має кілька пляшкових шийок. Перше пов'язано з механізмом кешування – через нього існує певна межа ПСП, що залежить від частоти процесора, такою, що вище цього значення не вдається перестрибнути, навіть використовуючи більш високочастотні режими. Наприклад, при середньому процесорі різниця у роботі з пам'яттю між DDR2 667 та 800 МГц може бути близько 1-3%, для реального завдання – взагалі мізерною. Тому краще всього вибирати оптимальну частоту і знижувати таймінги - на них контролер дуже добре відгукується. Тому впроваджувати DDR3 сенсу немає ніякого – великі таймінги лише зашкодять, приросту взагалі може бути. Також проблема AMD зараз – повільна (попри SSE128) обробка SIMD інструкцій. Саме тому Core 2 дуже сильно обганяє K8/K10. ALU, який завжди був сильним місцем Intel, став ще сильнішим, і в деяких випадках може бути в рази швидше за свого побратима в Phenom'і. Тобто основне лихо процесорів AMD – слабка «математика».
Взагалі, слабкі ланки дуже залежить від конкретного завдання. Були розглянуті лише «епохальні». Так, у деяких завданнях швидкість може упертися в обсяг ОЗУ або швидкість дискової підсистеми. Тоді додається більше пам'яті (об'єм визначається за допомогою лічильників продуктивності) і ставляться RAID масиви. Швидкість ігор може бути підвищена відключенням вбудованої звукової карти та покупкою нормальної дискретної – Creative Audigy 2 або X-Fi, які менше вантажать процесор, обробляючи ефекти своїм чіпом. Це більшою мірою відноситься до звукових карт AC'97 і меншою до HD-Audio (Intel Azalia), оскільки в останній була виправлена проблема високого завантаження процесора.
Пам'ятай, що система завжди повинна братися під конкретні завдання. Найчастіше, якщо відеокарту можна підібрати збалансовану (і то вибір за ціновими категоріями буде залежати від цін, що сильно різняться по різних місцях), то, скажімо, з дисковою підсистемою така можливість не завжди є. RAID 5 потрібний дуже небагатьом, але для сервера це незамінна річ. Те саме відноситься до двопроцесорної або багатоядерної конфігурації, марної в офісних додатках, але це "must have" для дизайнера, що працює в 3Ds Max.
Теорія обмежень систем була сформульована у 80-ті роки ХХ ст. та стосувалося управління виробничими підприємствами. Коротко її суть зводиться до того, що у кожній виробничій системі діють обмеження, що стримують ефективність. Якщо усунути ключове обмеження, система запрацює значно ефективніше, ніж намагатися впливати на всю систему відразу. Тому процес удосконалення виробництва слід розпочинати з усунення вузьких місць.
Зараз термін bottleneck може використовуватися для будь-якої галузі — у сфері послуг, розробці програмного забезпечення, логістиці, повсякденному житті.
Що таке bottleneck
Визначення bottleneck звучить як місце у виробничій системі, в якому виникає навантаження, тому що потік матеріалів надходить дуже швидко, але не може бути так само швидко перероблений. Часто це станція з меншою потужністю ніж попередній вузол. Термін стався з аналогії з вузькою шийкою пляшки, яка уповільнює шлях рідини назовні.

Bottleneck - вузьке місце у виробничому процесі
На виробництві ефект пляшкового шийки викликає простої та виробничі витрати, знижує загальну ефективність та збільшує терміни відвантаження продукції замовникам.
Існує два типи вузьких місць:
- Короткострокові вузькі місця- Викликані тимчасовими проблемами. Хороший приклад — лікарняна або відпустка ключових співробітників. Ніхто в команді не може повноцінно замінити їх і робота зупиняється. На виробництві це може бути поломка одного з групи верстатів, коли його навантаження розподіляється між робочим обладнанням.
- Довгострокові вузькі місця- Діють постійно. Наприклад, постійна затримка місячних звітів у компанії через те, що одна людина має обробити величезну кількість інформації, яка надійде до неї лавиною наприкінці місяця.
Як визначити bottleneck у виробничому процесі
Існує кілька способів пошуку bottleneck на виробництві різного рівня складності, із застосуванням спеціальних інструментів та без. Почнемо з простіших способів, заснованих на спостереженні.
Черги та затори
Процес на виробничій лінії, який збирає перед собою найбільшу чергу з одиниць незавершеного виробництва, зазвичай є пляшковим шийкою. Такий спосіб пошуку bottleneck підходить для штучного конвеєрного виробництва, наприклад, на лінії розливу. Добре видно, де лінії накопичуються пляшки, і який механізм має недостатню потужність, часто ламається або обслуговується недосвідченим оператором. Якщо на лінії кілька місць скупчення, то ситуація складніша, і потрібно використовувати додаткові методи, щоб знайти найкритичніше вузьке місце.
Пропускна спроможність
Пропускна спроможність усієї виробничої лінії прямо залежить від виходу обладнання bottleneck. Ця характеристика допоможе знайти головне пляшкове шийку процесу виробництва. Збільшення випуску одиниці устаткування, яка є вузьким місцем, істотно вплине загальний випуск лінії. Перевіривши по черзі все обладнання, можна виявити bottleneck - тобто той крок, збільшення потужності якого найбільше вплине на вихід всього процесу.
Повна потужність
Більшість виробничих ліній відстежують відсоток завантаження кожної одиниці обладнання. Верстати та станції мають фіксовану потужність та в процесі виробництва використовуються на певний відсоток від максимальної потужності. Станція, яка використовує максимум потужності - bottleneck. Таке обладнання стримує процент використання потужності іншого обладнання. Якщо ви збільшите потужність bottleneck, то потужність усієї лінії зросте.
Очікування
Процес виробництва також враховує час простоїв та очікування. Коли на лінії є пляшкова шийка, то обладнання, що йде одразу ним, довго простоює. Bottleneck затримує виробництво і наступний верстат не отримує достатньо матеріалу, щоб працювати безперервно. Коли ви виявите верстат з довгим часом очікування, то шукайте на попередньому кроці пляшку.
Крім спостереження за виробництвом, для виявлення вузьких місць використовуються такі інструменти:
Value Stream Mapping – карта створення потоків цінності
Як тільки ви з'ясуйте причину чи причини вузьких місць, потрібно визначити діїдля розширення пляшкової шийки та нарощування виробництва. Можливо, вам знадобиться перемістити співробітників у проблемну зону або найняти додатковий персонал та придбати обладнання.
Пляшкова шийка може виникнути там, де оператори переналаштовують обладнання для виробництва іншого продукту. У такому разі слід подумати, як скоротити простої. Наприклад, змінити графік виробництва, щоб зменшити кількість переналагодження або зменшити їх вплив.
Як зменшити вплив вузьких місць
Bottleneck менеджмент пропонує виробничим компаніям використати три підходи, щоб зменшити вплив вузьких місць.
Перший підхід
Збільшення потужності існуючих вузьких місць.
Існує кілька способів збільшити потужність вузьких місць:
- Додайте ресурси в обмежуючий процес. Необов'язково наймати нових працівників. Крос-функціональне навчання персоналу може зменшити вплив вузьких місць із незначними витратами. У такому разі робітники обслуговуватимуть одразу кілька станцій та полегшуватимуть проходження вузьких місць.
- Забезпечте безперебійне подання деталей на вузьке місце. Завжди слідкуйте за незавершеним виробництвом перед вузьким місцем, керуйте подачею ресурсів на станцію bottleneck, враховуйте овертайми, протягом яких обладнання також завжди має деталі для обробки.
- Переконайтеся, що вузьке місце працює лише з якісними деталями. Не витрачайте потужність та час роботи вузького місця на опрацювання шлюбу. Розташуйте точки контролю якості перед станціями bottleneck. Це підвищить пропускну здатність процесу.
- Перевірте графіки виробництва. Якщо у процесі випускається кілька різних продуктів, які вимагають різного часу роботи bottleneck, скоригуйте графік виробництва так, щоб загальний попит на bottleneck зменшився
- Збільште час роботи обладнання, що обмежує. Нехай bottleneck працює довше, ніж інше обладнання. Призначте оператора, який обслуговуватиме процес під час обідніх перерв, планових простоїв і, якщо потрібно, понаднормово. Хоча цей метод не зменшить час циклу, він буде підтримувати роботу bottleneck доки інше обладнання простоюватиме.
- Скоротіть простої. Уникайте планових та позапланових простоїв. Якщо обладнання bottleneck вийде з ладу під час робочого процесу, негайно надішліть ремонтну бригаду, щоб відремонтувати та запустити його. Також постарайтеся скоротити час переналагодження обладнання з одного продукту на інший.
- Удосконаліть процес саме у вузькому місці. Використовуйте VSM, щоб усунути дії, що не додають цінності, і скоротити час на додавання цінності, позбавившись втрат. У результаті ви отримаєте коротший час циклу.
- Перерозподіліть навантаження на bottleneck. Якщо можливо, розділіть операцію на частини та призначте їх на інші ресурси. У результаті ви отримаєте коротший цикл і збільшену потужність.

Другий підхід
Продаж надлишків виробництва, які випускає обладнання, що не відноситься до пляшкового шийки.
Наприклад, у вас на лінії 20 ін'єкційних пресів, а ви використовуєте лише 12 із них, тому що обладнання bottleneck не може переробити випуск усіх 20 пресів. У цьому випадку ви можете знайти інші компанії, які зацікавлені у субпідряді на операції лиття під тиском. Ви будете у прибутку, тому що отримаєте від субпідрядників більше, ніж ваші змінні витрати.
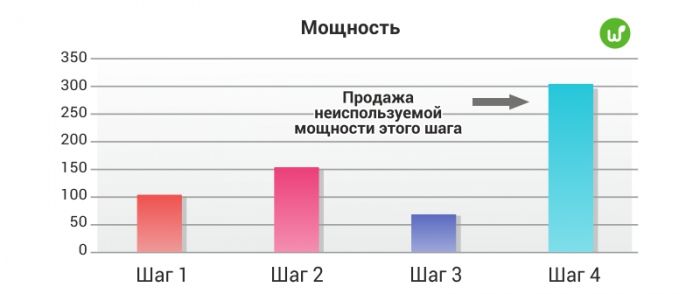
Третій підхід
Скорочення потужності, що не використовується.
Третій варіант оптимізації виробництва - розпродати обладнання з екстра потужністю та скоротити або перемістити персонал, який його обслуговує. В цьому випадку потужність всього обладнання буде зрівняна.

Приклади bottleneck поза виробництвом
Транспорт
Класичний приклад — пробки на дорогах, які можуть постійно утворюватися в певних місцях, або тимчасово з'являтися під час ДТП або проведення дорожніх робіт. Інші приклади – шлюз на річці, навантажувач, залізнична платформа.
Комп'ютерні мережі
Повільний Wi-Fi-роутер, підключений до ефективної мережі з високою пропускною здатністю, є вузьким місцем.
Комунікація
Розробник, який шість годин на день проводить на нарадах, і лише дві години пише код.
Програмне забезпечення
У додатку також є вузькі місця - це елементи коду, на яких програма "гальмує", змушуючи користувача чекати.
"Залізо" комп'ютера
Вузькі місця в комп'ютері - це обмеження апаратних засобів, за яких потужність усієї системи обмежується одним компонентом. Часто процесор розглядається як обмежуючий компонент відеокарти.
Бюрократія
У повсякденному житті ми часто зустрічаємося з вузькими місцями. Наприклад, коли раптово закінчуються бланки для паспортів або прав водія і вся система зупиняється. Або коли потрібно пройти медогляд, а кабінет флюорографії працює лише три години на день.
Вердикт
Вузькі місця у виробництві, менеджменті та житті – це точки потенційних покращень.
Розширення bottleneck дасть відчутний приріст продуктивності та ефективності.
А не звертати уваги на обмежуючі елементи системи — значить недоотримувати прибуток і працювати гірше за свої можливості.
Доброго вам дня!
Доброго дня, нічого не віщувало поганого. Але ось прийшла проблема - швидкість роботи якоїсь програми стала неприйнятно маленькою, причому ще тиждень/місяць/день тому все було добре. Вирішити її треба швидко, витративши якнайменше часу. Проблемний сервер на базі Windows Server 2003 або пізнішої версії.
Сподіваюся нижченаведена писанина буде досить короткою і зрозумілою і до того ж корисною як для адміністраторів-початківців, так і для більш серйозних товаришів, бо завжди можна знайти щось нове для себе. Не варто відразу кидатися досліджувати поведінку програми. Перш за все варто подивитися, чи вистачає продуктивності сервера зараз? Чи немає якихось «пляшкових шийок», що обмежують його продуктивність?
У цьому нам допоможе perfmon - досить потужний інструмент, що йде разом із Windows. Почнемо з того, що дамо визначення «пляшковому шийку» - це ресурс, який досяг своєї межі використання. Зазвичай вони виникають через некоректне планування ресурсів, аппартні проблеми або неправильну поведінку програми.
Якщо відкрити perfmon, то ми побачимо десятки і сотні всіляких датчиків, і кількість не сприяє швидкому розслідуванню даної проблеми. Так що для початку виділимо 5 основних можливих «пляшкових шийок», щоб скоротити список досліджуваних датчиків.
Це будуть процесор, оперативна пам'ять, система зберігання даних (HDD/SSD), мережа та процеси. Далі ми розглянемо кожен із цих пунктів, які датчики будуть нам потрібні та порогові значення для них.
Процесор
Перевантажений завданнями процесор явно не сприяє швидкій роботі програм. Для вивчення його ресурсів ми виділимо лише 4 датчики:
Processor\% Processor Time
Вимірює відношення часу роботи процесора на час простою у відсотках. Найзрозуміліший датчик, завантаження процесора. MS рекомендує змінювати процесор більш швидкий, якщо значення вище 85%. Але це залежить від багатьох факторів, треба знати свої потреби та особливості, тому що це значення може змінюватись.
Processor\% User Time
Показує, скільки часу процесор проводить у user space. Якщо значення велике, це означає, що програми забирають багато процесорного часу, варто глянути ними, т. до. назріває необхідність їх оптимізації.
Processor\% Interrupt Time
Вимірює час, який процесор витрачає очікування відповіді переривання. Даний датчик може показати наявність "залізних" проблем. MS рекомендує починати хвилюватися, якщо це значення перевищує 15%. Це означає, що пристрій починає відповідати дуже повільно на запити і його слід перевірити.
System\Processor Queue Length
Показує кількість потоків у черзі, які чекають свого часу на виконання. MS рекомендує задуматися над зміною процесора на має більшу кількість ядер, якщо дане значення перевищує кількість ядер, помножених на два.
Оперативна пам'ять
Нестача оперативної пам'яті може сильно позначитися на загальну продуктивність системи, змушуючи систему активно використовувати повільний HDD для свопування. Але навіть якщо на сервері встановлено багато ОЗУ, пам'ять може «витікати». Витік пам'яті – це неконтрольований процес зменшення кількості вільної пам'яті, пов'язаний із помилками у програмах. Також варто згадати, що для Windows обсяг віртуальної пам'яті є сумою ОЗУ та файлу підкачування.
Memory\% Committed Bytes in Use
Показує використання віртуальної пам'яті. Якщо значення перевищило 80%, варто подумати про додаванні ОЗУ.
Memory\Available Mbytes
Показує використання ОЗУ, зокрема кількість доступних мегабайт. Якщо значення становить менше 5%, то знову-таки слід подумати про додавання ОЗП.
Memory\Free System Page Table Entries
Кількість вільних елементів таблиці сторінок. А воно обмежене, крім того, в наші дні популярність набувають сторінки в 2 і більше МБ, замість класичних 4кБ, що не сприяє їх великій кількості. Значення менше 5000 може свідчити про витік пам'яті.
Memory\Pool Non-Paged Bytes
Розмір даного пулу. Це клаптик пам'яті ядра, який містить важливі дані і не може бути вивантажений у swap. Якщо значення перевищило 175 МБ, то швидше за все це витік пам'яті. Зазвичай це супроводжується появою подій 2019 року в системному журналі.
Memory\Pool Paged Bytes
Аналогічно попередньому, але ця область можна вивантажувати на диск (swap), якщо вони не використовуються. Для цього лічильника значення вище 250 МБ вважаються критичними, зазвичай супроводжується появою подій 2020 у системному журналі. Також говорить про витік пам'яті.
Memory\Pages per Second
Кількість звернень (запис/читання) до page file за секунду через відсутність необхідних даних у ОЗУ. І знову значення понад 1000 натякає на витік пам'яті.
Жорсткий диск
Досить важливий елемент, який може зробити істотний внесок у продуктивність системи.
LogicalDisk\% Free Space
Відсоток вільного місця. Цікавлять лише розділи, що містять системні файли - ОС, файл/файли підкачування і т.д. MS рекомендує подбати про збільшення дискового простору, якщо вільного місця залишилося менше 15%, тому що при критичних навантаженнях воно може різко закінчитися (temp файлами, оновлення Windows або тим же файлом підкачування). Але, як кажуть, “it depends” і треба дивитися реально доступний розмір простору, т.к. той же файл підкачки може бути жорстко фіксований, на temp"и накладені квоти, що забороняють їм розростатися, а оновлення лунають порційно і рідко, або їх немає взагалі.
PhysicalDisk\% Idle Time
Показує, скільки часу диск не діє. Рекомендується замінити диск на більш продуктивний, якщо лічильник знаходиться нижче 20% кордону.
PhysicalDisk\Avg. Disk Sec/Read
Середній час, необхідний жорсткому диску для читання даних із самого себе. Вище 25мс – це вже погано, для SQL сервера та Exchange рекомендується 10мс і менше. Рекомендація ідентична попередньої.
PhysicalDisk\Avg. Disk Sec/Write
Ідентично PhysicalDisk\Avg. Disk Sec/Read, лише для запису. Критичний поріг теж дорівнює 25мс.
PhysicalDisk\Avg. Disk Queue Length
Показує середню кількість I/O операцій, які чекають, коли жорсткий диск стане для них доступним. Рекомендується починати турбуватися, якщо це число вдвічі перевищує кількість шпинделів в системі (у разі відсутності raid-масивів кількість шпинделів дорівнює кількості жорстких дисків). Порада колишня - більш продуктивна HDD.
Memory\Cache Bytes
Об'єм пам'яті, який використовується для кеша, частина якого є файловим. Об'єм більше 300МБ може говорити про проблему з продуктивністю HDD або наявність програми, що активно використовує кеш.
Мережа
У світі без неї нікуди - величезна кількість даних транслюються саме у мережі.
Network Interface\Bytes Total/Sec
Кількість даних, що передаються (send/receive) через мережевий адаптер. Значення, що перевищує 70% від пропускної спроможності інтерфейсу, говорить про можливу проблему. Потрібно або замінити карту більш продуктивну, або додати ще одну для розвантаження першої.
Network Interface\Output Queue Length
Вказує кількість пакетів, що стоять у черзі на відправлення. Якщо значення перевалило за 2, варто подумати про заміну карти на більш продуктивну.
Процеси
Продуктивність сервера може катастрофічно впасти, якщо є неоптимізована програма або програма починає поводитися «неправильно».
Process\Handle Count
Кількість дескрипторів, що обробляються процесом. Це може бути як файли, і ключі реєстру. Кількість цих, що перевищує 10000 може бути показником неправильної роботи програми.
Process\Thread Count
Кількість потоків усередині процесу. Варто уважніше вивчити поведінку програми, якщо різниця між мінімальним і максимальним числом перевищить 500.
Process\Private Bytes
Показує кількість пам'яті, що виділяється процесом, яке може бути надано іншим процесам. Якщо коливання даного показника перевищить 250 між мінімумом і максимумом, то це говорить про можливий витік пам'яті.
У більшості вищенаведених лічильників немає чіткого показника того, що в системі з'явилося «пляшкове шийка». Всі наведені значення будувалися за середньостатистичними результатами і можуть змінюватись для різних систем у широкому діапазоні. Щоб скористатися даними лічильниками грамотно, ми повинні знати хоча б показники системи за нормальної роботи. Це називається baseline performance – perfmon лог, знятий з працюючої свіжовстановленої (останнє необов'язково, ніколи не пізно зняти даний лог або вести облік зміни baseline продуктивності в довгостроковій перспективі) системи, яка не має проблем. Це досить важливий момент, що часто багатьма опускається, хоча в майбутньому він може серйозно скоротити можливий простий системи та у явній формі прискорити аналіз отриманих даних із наведених вище лічильників.
Взято з https://ua.intel.com/business/community/?automodule=blog&blogid=57161&sh...
0 0Якщо у сучасної людини запитати, з яких основних частин складається комп'ютер, то, мабуть, вона наведе досить довгий список, у перших рядках якого будуть системний блок, клавіатура та монітор. Неважко здогадатися, що подібний список навряд чи підходить для характеристики комп'ютера, що управляє мікрохвильовою піччю, системою запалювання автомобіля або космічним апаратом. Загалом, у ньому не більше спільного з реальністю, ніж у твердженні про те, ніби малиновий піджак – відмінна риса всіх хребетних.
Будь-який комп'ютер, незалежно від його архітектурних особливостей та призначення, складається з центрального процесора та оперативної пам'яті, які за необхідності можуть бути доповнені периферійними пристроями. Останні застосовуються в основному для того, щоб комп'ютер міг обмінюватися інформацією із зовнішнім світом. Але загалом його продуктивність визначається узгодженою роботою саме процесора та пам'яті. І саме тут останнім часом намітилося вузьке місце.
У IBM PC, першому масовому 16-розрядному персональному комп'ютері, що з'явився трохи більше 20 років тому, був використаний процесор Intel 8088 - молодший брат Intel 8086, який відрізняється від нього вдвічі більш вузькою зовнішньою шиною даних. Таке рішення було економічно виправданим, тому що дозволяло використовувати восьмирозрядну периферію, завдяки чому новий комп'ютер не надто відрізнявся за ціною від своїх восьмирозрядних побратимів. Але якщо попередній процесор Intel 8086 здійснював синхронну вибірку та виконання команд, то у нового процесора ці дії виконувались асинхронно – з'явилася черга команд, що заповнювалася тоді, коли не було інтенсивного обміну процесора з областю даних. Це дозволило більш ефективно використовувати пропускну здатність шини даних, і зменшення її ширини вдвічі не призвело до суттєвого падіння продуктивності.
Тоді пам'ять практично не затримувала виконання команд: процесор працював на тактовій частоті 4,77 МГц і навіть адресу він обчислював набагато довше, ніж пам'ять видавала необхідні дані. Однак швидкість процесора характеризується тактовою частотою, а швидкість пам'яті - часом доступу, який не схильний до такого запаморочливого прогресу: тактова частота зросла майже в 500 разів, а час доступу скоротилося лише приблизно на порядок. Але якщо час доступу, скажімо, 100 нс, то за 10 МГц це відповідає одному такту процесора, за 40 МГц - чотирьох тактів, а за 100 МГц - вже десяти. З іншого боку, вдосконалювалася архітектура процесорів, отже одні й самі команди стали виконуватися набагато меншу кількість тактів (див. табл. 1).
Розробники враховували тенденції, що виникають. IBM PC AT вийшов вже з повною 16-розрядною шиною даних, а IBM AT-386 – з повною 32-розрядною. Такою була розрядність комп'ютерів і 486 процесорі. Дальше більше. Ширина зовнішньої шини даних Pentium становила 64 розряди, тобто вдвічі перевищувала розрядність процесора. А для графічних процесорів (часто званих 3D-акселераторами) вона становить 128-256 розрядів.
Збільшення ширини шини - єдиний спосіб обійти низьку швидкість роботи пам'яті. Починаючи зі старших моделей 386 в комп'ютерах стали застосовувати кеш-пам'ять - невеликий обсяг швидкодіючої пам'яті, що є буфером між повільною основною пам'яттю і процесором.
Сучасні модулі пам'яті призначені до роботи у вузькому діапазоні частот, тому часові діаграми їх роботи оптимізуються лише однієї, номінальної, частоти. Отже, при використанні нижчих частот продуктивність пам'яті буде знижуватися пропорційно.
Донедавна частота зовнішньої шини процесора Front Side Bus (FSB) мала збігатися з частотою тактування оперативної пам'яті. Низька частота шини у процесорів Celeron (66 МГц) у своїй обмежувала продуктивність даного класу процесорів. Останні ж чіпсети дозволяють тактувати пам'ять більш високою частотою, що може досить суттєво позначитися на загальній продуктивності. Для дослідження цього питання було використано системну плату Gigabyte GA-6VTX на чіпсеті VIA Apollo Pro 133T, що дозволяє незалежно встановлювати як зовнішню частоту процесора, так і частоту тактування оперативної пам'яті. На неї по черзі встановлювалися два процесори, що відрізняються частотою зовнішньої шини: Celeron-566 (FSB 66 МГц) та Celeron-1000 (FSB 100 МГц). Набір тестів – традиційний для нашого журналу. Усі тести проводилися в однозадачній ОС (DOS Mode Windows 98 SE). Природно, кеш-пам'ять при проведенні вимірювань не відключалася, що також мало чималий вплив (іноді визначальний, але про це нижче) на результати.
Під час читання, запису та пересилання 4-Мбайт масиву виявилися цілком певні закономірності (див. табл. 2).
По-перше, збільшення частоти тактування пам'яті зі 100 до 133 МГц при FSB 66 МГц не призвело до зміни результатів. Це справедливо як для послідовного доступу, а й взагалі всім проведених експериментів. У чому тут справа: чи FSB не здатна "переварити" більш ніж півторакратне збільшення частоти пам'яті, чи реальна частота тактування "заморожується" на 100, коли BIOS Setup показує 133, - сказати важко.
По-друге, швидкість виконання значної частини операцій залежить лише від частоти пам'яті, а чи не від частоти процесора.
По-третє, реально виміряні швидкості доступу до пам'яті часто виявляються значно нижчими від того, що можна було б очікувати, виходячи з найпростіших оцінок.
Як альтернативу послідовному доступу можна застосувати довільний. Усередині 32-Мбайт області випадково обчислювався адресу, та був за цією адресою проводилося читання чи запис одного байта (рис. 1).
Надзвичайно низька швидкість обміну пояснюється двома факторами. По-перше, для початкового завдання адреси потрібно багато часу (див. врізання ). По-друге, операції читання/запису буферизовані кешем, а обмін із нею здійснюється лише порціями по 32 байти. Іншими словами, щоб рахувати з пам'яті 1 байт, необхідно перенести в кеш 32. На закінчення зазначу, що процедура обчислення випадкової адреси звичайно ж займає деякий час, проте застосований алгоритм дозволяє при зменшенні обсягу даних до об'єму кеша L2 робити вибірку зі швидкістю більше 70 Мбайт/с для застосовуваного процесора 1 ГГц.
p align="justify"> Різний характер залежності продуктивності від частоти процесора і пам'яті для різних типів додатків можна бачити на рис. 2.

Для одноманітності за одиницю продуктивності прийнятий процесор із частотою 566 МГц та пам'яттю, що працює на 66 МГц. Кривими позначено такі тестові програми:
- Розв'язання системи диференціальних рівнянь у приватних похідних (СДУЧП) на процесорі 566 МГц за обсягом даних 40 Мбайт.
- Рішення СДУЧП на процесорі 1000 МГц за тих же умов.
- Знаходження простих чисел методом "решета Ератосфена" (РЕ) на процесорі 566 МГц за обсягом масивів 40 Мбайт.
- РЕ на процесорі 1000 МГц за того ж обсягу масивів.
- Швидке сортування 16-Мбайт масиву на процесорі 566 МГц.
- Швидке сортування 16-Мбайт масиву на процесорі 1 ГГц.
- Знаходження найкоротшого шляху у графі методом Дейкстри на 566-МГц процесорі. Об'єм масивів 300 Кбайт (більше подвоєного обсягу кеш-пам'яті).
- Знаходження найкоротшого шляху у графі на 1-ГГц процесорі за тих самих умов.
З наведених даних видно, що більшість додатків найбільш чутлива до частоти процесора. На рис.2 їм відповідають горизонтальні криві поблизу одиниці для частоти 566 МГц та поблизу 1,7-1,8 для 1000 МГц. Найбільш чутливим до частоти пам'яті виявилося "решета Ератосфена", при цьому з 66-МГц пам'яттю продуктивність практично не залежала від частоти процесора. Графіки для таких додатків мають вигляд похилих ліній, для яких збільшення частоти вдвічі відповідає такому збільшення продуктивності, при цьому залежність від частоти процесора відсутня. Деякий компроміс спостерігається під час вирішення системи диференціальних рівнянь. Продуктивність залежить від частоти пам'яті, але не прямо пропорційно, а набагато слабше, крім того, при частоті пам'яті 66 МГц процесор Celeron 1 ГГц демонструє лише на чверть більш високу продуктивність порівняно з 566 МГц.
Хочеться порівняти на прикладі ще одного завдання, а також досліджувати вплив кеш-пам'яті.
У ті далекі часи, коли комп'ютери займали кілька поверхів будівлі та використовувалися виключно для наукових розрахунків, оцінці продуктивності вже приділялося чимало уваги. Щоправда, затримок, пов'язаних із пам'яттю, тоді не було, а найскладнішими вважалися обчислення з плаваючою комою. Ось для таких обчислень і було написано тест Донгарра - рішення системи лінійних рівнянь. Результати деякого узагальнення цього тесту наведено на рис. 3. Тепер виявилося, що самі обчислення з плаваючою комою можна виконати набагато швидше, ніж записати результати цих обчислень на згадку.

Невисока продуктивність при невеликих масивах пояснюється тим, що сучасні суперскалярні процесори з конвеєрною архітектурою добре виконують безперервну послідовність команд, цикли і виклики процедур - дещо гірші, а накладні витрати саме на ці операції зростають із зменшенням розмірів масивів. До досягнення обсягом даних обсягу кеш-пам'яті продуктивність зростає, причому визначається виключно частотою процесора. При переповненні кешу бачимо різке падіння продуктивності, досягає десятикратного. При цьому криві в перехідній області спочатку розходяться, а потім знову сходяться, але вже за іншою ознакою - частотою пам'яті. Тактова частота процесора втрачає свою роль, першому плані виходить частота пам'яті.
На щастя, значна частина реальних додатків не досягає таких обсягів даних, що одночасно оброблюються, при яких тактова частота процесора вже перестає грати роль. Обробку текстур, необхідну кожному кадрі, перебирає графічний процесор, а там зовсім інші і частоти, і ширина шини. А решта об'ємних даних, будь то відеофільм, архів або багатосторінковий документ, як правило, обробляються невеликими порціями, що вміщуються в кеш-пам'ять. Але з іншого боку, кеш-пам'ять теж треба заповнювати. Та й зниження продуктивності "всього" вдвічі-втричі або навіть на десятки відсотків замість десятикратного навряд чи може втішити.
З проведених вимірювань випливає і ще один висновок: якщо чіпсет допускає асинхронну роботу процесора і пам'яті, це нівелює різницю у продуктивності через розбіжності у FSB, яка є, наприклад, Celeron і Pentium !!!.
Від редакції:хоча отримані висновки з упевненістю можна віднести лише до плат на основі набору мікросхем VIA Apollo 133T, але загалом цей підхід може бути застосований і для оцінки ефективності переходу на 533-МГц шину в сучасних платах.
Як працює динамічна пам'ять
Центральною частиною мікросхеми динамічної пам'яті є матриця конденсаторів розміром MxN, де M і N зазвичай дорівнюють двом певною мірою. Кожен конденсатор може бути в одному з двох станів: зарядженому або розрядженому, таким чином він зберігає 1 біт інформації.
Адреса в мікросхему пам'яті передається в два етапи: спочатку молодша половина адреси фіксується в регістрі адреси сигналом RAS (строб адреси рядка), а потім старша - сигналом CAS (строб адреси стовпця). При зчитуванні даних із пам'яті після фіксації молодша частина адреси подається на дешифратор рядків, і з нього - на матрицю, у результаті рядок конденсаторів матриці повністю підключається до входу підсилювачів зчитування. У процесі зчитування конденсатори розряджаються, отже, інформація в матриці втрачається. Щоб не допустити цього, щойно лічені рядки даних знову записуються в рядок конденсаторів матриці - відбувається регенерація пам'яті. До того моменту, коли рядок з матриці потрапила в буфер підсилювача зчитування, на дешифратор адреси стовпця вже подано старшу половину адреси і за допомогою цього дешифратора вибирається один-єдиний біт інформації, що зберігається за адресою, зафіксованою в регістрі адреси. Після цього лічені дані можна подати вихід мікросхеми. При записі інформації спочатку рядок також зчитується повністю, потім змінюється потрібний біт і рядок записується на колишнє місце. Збільшення розрядності до 1, 2, 4 або 8 байт досягається паралельною роботою кількох мікросхем пам'яті або кількох матриць в одній мікросхемі.
Як бачимо, для доступу до осередку динамічної пам'яті потрібно зробити багато послідовних операцій, а тому час доступу виявляється досить великим - сьогодні це 35-50 нс, що відповідає 5-7 тактам зовнішньої шини.
Пам'ять, що працює, як описано вище (DRAM – динамічна пам'ять довільного доступу), застосовувалася у перших персональних комп'ютерах. В одному корпусі зберігався обсяг інформації до 64 кбіт. Але якщо операції з адресою неминуче займають багато часу, то чи не можна обійти це обмеження? Адже процесору часто потрібні довгі ланцюжки байтів, що зберігаються в пам'яті підряд, наприклад, при виконанні послідовності команд або при обробці рядків і масивів даних. І рішення було знайдено: після передачі мікросхеми адреси першого елемента кілька наступних зчитувалося лише за допомогою сигналів шини управління, без передачі нової адреси, що виявилося приблизно вдвічі швидше. Така пам'ять отримала назву FPM RAM (пам'ять зі швидкою сторінковою організацією) і надовго стала єдиним типом оперативної пам'яті, що використовується в персональних комп'ютерах. Для позначення тимчасових характеристик такої пам'яті застосовувалися послідовності цифр: наприклад, "7-3-3-3" означало, що отримання першої порції даних потрібно витратити 7 тактів системної шини, але в наступні - по 3. Проте відрив тактової частоти процесора від частоти системної шини, з одного боку, і прогрес технології, що дозволило скоротити кількість тактів, що витрачається обчислювальним блоком на одну операцію, з іншого, порушили питання про подальше вдосконалення технології роботи оперативної пам'яті.
Наступним етапом була розробка EDO RAM - пам'яті зі збільшеним часом виведення даних, коли стало можливим поєднати отримання чергового блоку даних із передачею "заявки" отримання наступного. Це дозволило на такт зменшити час доступу: "6-2-2-2". Однак EDO RAM дуже скоро була витіснена пам'яттю типу SD RAM (синхронна), за рахунок чергування блоків час доступу виявилося можливим зменшити до "5-1-1-1-1-1-1-1". Одночасно був застосований деякий маркетинговий хід: якщо при позначенні часу доступу до пам'яті типу FPM та EDO RAM прийнято було вказувати час першого звернення, яке становило 60-80 нс, то для SD RAM стали вказувати час другого та наступних, що становило вже 10-12 нс для тих самих тактових частот і, отже, близького часу першого звернення. Продуктивність підсистеми пам'яті у своїй зросла на десятки відсотків, тоді як числа, що позначають час доступу до пам'яті, зменшилися у кілька разів.
SDRAM і досі є основним типом пам'яті для процесорів Intel Pentium !!! та Celeron. Поряд з нею можуть використовуватися і нові розробки: DDR RAM (точніше, DDR SDRAM, але ми будемо користуватися зазначеним позначенням), що застосовується в основному з процесорами AMD Athlon і Duron, що працює на тих же частотах (100-133 МГц), але дозволяє передавати дані до двох разів за такт: по передньому та задньому фронту (тому з'явилося таке поняття, як ефективна частота, в даному випадку 200-266 МГц), та орієнтована на застосування в системах з Pentium-4 RDR RAM (Rambus RAM), що працює на частотах 300–533 МГц (ефективна частота 600–1066 МГц).
Якщо для SDRAM (тепер часто званої SDR DRAM) було прийнято позначення PC-100 і PC-133, що означають можливість роботи на 100 і 133 МГц відповідно, то нових типів пам'яті, скажімо PC-2100, цифри позначають не частоту понад 2 ГГц , А лише "пікову" швидкість передачі даних. Слово "пікова" взято в лапки тому, що в яких би ідеальних умовах ми не проводили вимірювання, отримане відношення кількості переданої інформації до витраченого на це часу не тільки не буде вказаним числам, але навіть не буде прагнути до них асимптотично. Справа в тому, що ця швидкість наведена для частини пакета з відрізаною першою порцією даних, тобто, як і для SDRAM, тільки для "другого та наступних". Для DDR RAM час першого звернення такий самий, як і для SDRAM, а наступних - вдвічі менше. Тому при послідовному доступі виграш у продуктивності становить десятки відсотків, а за довільного - взагалі відсутня.